02-02 배열
가장 기본적인 선형 자료구조로 배열(array)를 먼저 살펴보겠습니다. 배열은 일종의 표와 같이 여러 개의 변수를 담는 공간이자, 0부터 시작되는 인덱스(index)가 존재합니다. (인덱스는 순서 개념으로 보시면 되겠습니다. 파이썬을 다뤄보신 분들은 인덱스가 0부터 시작되는 것에 익숙하실 겁니다.) 아래 표에서 각각의 값마다 인덱스가 할당된 것을 볼 수 있습니다. 배열 자료는 자신이 원하는 특정한 인덱스에 직접적으로 접근할 수 있으며, 수행 시간을 시간 복잡도로 표현하면 $O\left(1\right)$입니다.
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 값 | 25 | 75 | 83 | 59 | 24 | 72 | 55 | 17 | 42 |
배열의 특징
컴퓨터 부품 중 램(RAM)은 메인 메모리로써 저장장치 중에서는 읽고 쓰는 속도가 빠른 편입니다. 그런데 컴퓨터에 조금 더 관심이 있으신 분들은 CPU 스펙 표에서 L2 또는 L3 캐시 메모리라는 걸 보신 적이 있을 지도 모르겠습니다. 이들 캐시 메모리는 CPU 코어와 더욱 직접적으로 정보를 주고 받으며 훨씬 더 빠른 속도를 낼 수 있습니다. 대개 L1부터 L3까지 세 가지 종류가 탑재되는데 숫자가 커질수록 용량은 커지지만 속도가 느려져서 CPU와의 직접적인 자료 전달로부터는 거리가 멀어지는 특징이 있습니다.
즉, CPU - L1 캐시 - L2 캐시 - L3 캐시 - RAM - 하드, SSD 등 기타 저장매체 순서로 연결된다고 보면 되겠습니다. 각 부품 별 용량과 속도의 경향성은 아래 그림을 참고해주세요.
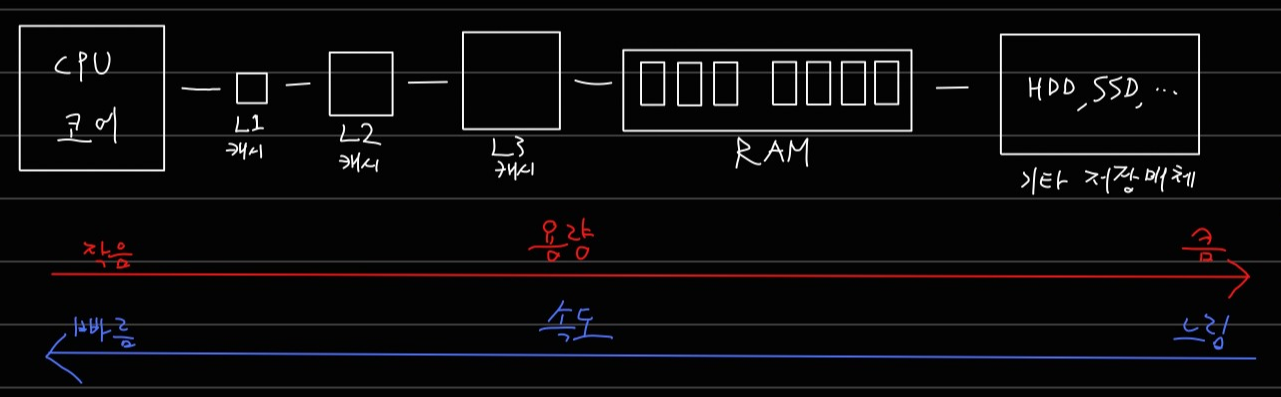
다시 배열 설명으로 돌아오자면, 배열의 장점은 바로 이 캐시 히트 가능성이 높다는 점입니다. 여기서 히트란 원하는 데이터가 해당 메모리에 존재하는지의 여부를 뜻하는데, 배열은 캐시 메모리로 옮기기가 수월한 편이라고 합니다. 그래서 히트 가능성이 높아지는 거고요. 따라서 원하는 데이터를 빠르게 조회할 수 있습니다. 하지만 일반적으로 배열은 연속적인 메모리 주소를 미리 지정해서 메인 메모리에 올려야 하기 때문에, 그 크기를 미리 지정해야 합니다. 이 때문에 데이터를 추가하거나 삭제하는 데 한계가 존재합니다.
위의 표에 설명한 데이터가 메모리에 어떻게 배열이 되는지를 아래 표로 나타내었습니다.
| 메모리 주소 | 0x0000 | 0x0004 | 0x0008 |
|---|---|---|---|
| 인덱스 | 0 | 1 | 2 |
| 값 | 25 | 75 | 83 |
참고 - 연결 리스트
다음 포스트에서 다룰 연결 리스트(linked list)를 잠시 알아보고 배열과 비교해보겠습니다. 윗 문단의 표에서 각 데이터의 메모리 주소는 연속적으로 할당된다고 표현합니다. 반면 연결 리스트는 컴퓨터의 메인 메모리 상에서 그 주소가 반드시 연속적이지는 않아도 괜찮습니다. 또한 배열과 달리 크기가 정해져 있지 않고, 동적으로 변경 가능합니다.
이게 가능한 이유는, 각 데이터에 포인터(pointer)라는 요소를 지정해서 다음 데이터의 위치를 가리킵니다. 배열은 데이터가 연속적으로 배치되니 다음 주소로 넘어가기만 하면 다음 데이터를 찾을 수 있지만, 연결 리스트는 다음 데이터의 위치가 어디 있든 간에 포인터를 집어넣어주어야 다음 데이터를 열람할 수 있습니다. 이 때문에 배열에 비해 삽입과 삭제가 간편하지만, 반드시 첫 번째 원소와 그로부터 이어지는 일련의 포인터들을 이용해서 하나하나 맨 앞부터 맨 뒤까지 원소를 찾는 탓에 데이터 검색 속도는 상대적으로 느리다는 단점이 있습니다.

참고 2 - 파이썬의 리스트 자료형
그리고 일견 파이썬의 리스트가 떠오르는 대목이기도 하고, 실제로 이름도 비슷하지만, 이 리스트는 컴퓨터공학의 연결 리스트와는 의미가 다릅니다. 파이썬의 리스트는 다른 프로그래밍 언어에서의 배열에 해당하는 포지션이며, 임의의 인덱스를 이용해 직접적인 접근이 가능하기 때문입니다.
사실 엄밀히 말하면 파이썬의 리스트는 동적 배열입니다. 배열의 용량이 가득 차면 append()라는 메서드를 이용해 원소를 추가한 후, 자동으로 크기를 증가시킵니다. 그러면서도 내부적으로 포인터(그것도 이중 포인터)를 사용하기 때문에 일부 연결 리스트의 장점도 가진 것이 특징입니다. 이 때문에 배열, 더 나아가서는 나중에 배우게 될 스택(stack)의 기능이 필요할 때 이 리스트 자료형을 그대로 사용할 수 있지만, 정작 또다른 자료구조인 큐(queue)의 기능은 제공하지 못해(좀 더 정확히는 큐의 기능이 효율적으로 구현되지 않음) 비효율적인 부분도 공존합니다.
정리해놓고 보니 돌연변이가 따로 없네
리스트 컴프리헨션
앞서 말했듯이 파이썬에서는 임의의 크기를 가지는 배열을 만들 수 있기 때문에, 이를 이용해 리스트 컴프리헨션(list comprehension)이라는 기법을 사용해 크기가 N인 1차원 배열을 만들 수 있습니다. 아래 예시 중 두 번째가 리스트 컴프리헨션을 이용한 예제입니다. 배열 안에 for문을 이용해 우리가 원하는 데이터를 갖는 배열을 만들 수 있습니다. 이와 같이 자유롭게 원소를 추가할 수 있어 코드 작성이 매우 편리해집니다.
어디까지나 작성자 입장에서
# [0, 0, 0, 0, 0]
n = 5
arr = [0] * n
print(arr)# [0, 1, 2, 3, 4]
n = 5
arr = [i for i in range(n)]
print(arr)
크기가 $M\times N$인 2차원 리스트(배열) 만들기
배열 그 자체를 다른 배열에 원소로 추가한다면, 2차원 리스트로 볼 수 있습니다. 아래 예시는 $3\times 5$ 크기의 2차원 배열을 초기화하는 예제입니다.
n = 3
m = 5
arr = [[0]*m for i in range(n)]
print(arr)
혹은 아래와 같이 리스트 컴프리헨션을 이중으로 사용해 서로 다른 원소로 배치되게끔 할 수도 있습니다.
n = 3
m = 5
arr = [[i*m +j for j in range(m)] for i in range(n)]
print(arr)앞으로 파이썬을 주력으로 다루신다면 리스트 컴프리헨션은 매우 변칙적이고 유용하게 사용 가능하니 여기저기 적용하면서 감을 익히심이 좋을 듯합니다.
배열을 초기화할 때 유의할 점
기본적으로 위에서 본 리스트는 메모리 주소를 반환합니다. 따라서 [[0]*m]*n 형태로 배열을 초기화했다가는 [0]이라는 리스트가 모두 같은 객체(object)로 인식되기 때문에, 같은 메모리 주소를 가리키는 $n$개의 원소가 리스트에 담기는 겁니다. 그러면 우리가 원하지 않는 요소까지 수정되고 삭제될 수 있기 때문에 이 부분은 염두에 둬야 합니다.
n = 3
m = 5
arr1 = [[0] * m] * n # 잘못된 초기화
arr2 = [[0] * m for i in range(n)] # 올바른 초기화
arr1[1][3] = 7
arr2[1][3] = 7
print(arr1)
print(arr2)
위 예시에서 잘못된 초기화를 한 경우 [1][3] 인덱스 뿐만 아니라 [0][3], [2][3]까지 한꺼번에 바뀌는 것을 볼 수 있습니다.
배열 직접 초기화하기
???: 답답하면 니들이 하든가
위에서와 같은 제약조건이 자신의 프로젝트에 반드시 적용되는 것은 아닌 덕분에, 자신이 원하는 임의의 값을 넣어서 바로 배열을 초기화한 뒤 사용할 수 있습니다.
arr = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(arr)
19일차 후기
처음으로 코딩 테스트라는 걸 알아보고 leetcode라는 사이트에 들어가봤습니다. 당시 저는 파이썬에 막 재미를 붙이던 터라 의욕 넘치게 테스트 문제를 풀어보려고 했고, 보기 좋게 실패를 반복했습니다. 뭔가 제대로 알고 넘어가야겠다는 생각에 사이트에서 제공하는 튜토리얼을 읽어보기 시작했고, 거기서 생전 처음 보는 연결 리스트 자료구조형을 만났습니다.
...이것이 제가 자료구조에 크게 데이고, 제대로 ML 분야를 파 보고자 공부하기 시작한 웃픈 이유입니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
* 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'[패스트캠퍼스 환급챌린지]딥러닝 > Chapter 2. 자료구조' 카테고리의 다른 글
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료구조 02-06 큐 (0) | 2023.03.14 |
|---|---|
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료구조 02-05 스택 (0) | 2023.03.13 |
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료 구조 02-04 파이썬에서의 리스트 (0) | 2023.03.12 |
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료 구조 02-03 연결 리스트 (0) | 2023.03.11 |
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료 구조 02-01 자료구조 개요 (0) | 2023.03.09 |