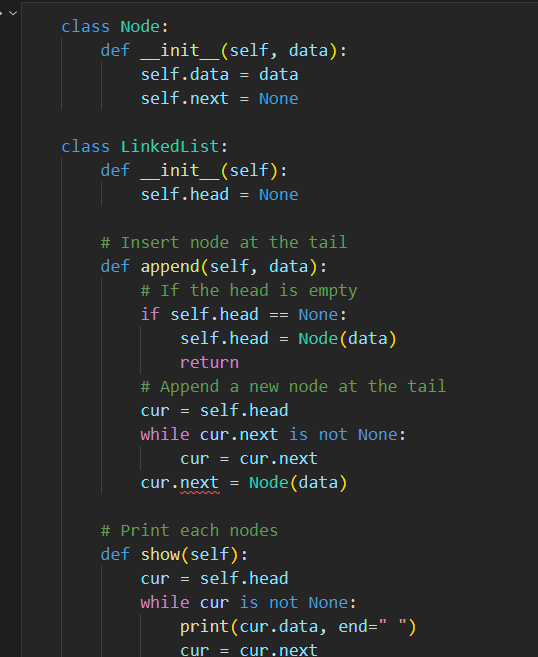
02-03 연결 리스트 def) 연결 리스트 (Linked List): 각 노드가 한 줄로 연결되어 있는 자료구조 지난 시간에 배열을 설명하면서 곁다리로 언급했던 연결 리스트에 대해 좀 더 자세히 알아보겠습니다. 각 노드는 (데이터, 포인터)의 한 쌍으로 묶여 있으며, 이러한 각 노드가 한 줄로 연결되어 있는 것이 연결 리스트입니다. 여기서 포인터는 다음 노드의 메모리 주소를 가리키는 역할을 합니다. 각 노드의 포인터가 다음 혹은 이전 노드를 가리키는 것을 연결성이라고 합니다. 연결 리스트를 이용하면 앞으로 배울 스택, 큐 등 다양한 자료구조를 구현할 수 있습니다. 다만, 우리가 데이터 사이언스와 ML 분야에서 주로 사용하는 파이썬은 연결 리스트를 활용하는 자료구조인 리스트(list)를 자체적으로 제공합..