01-09 베이즈 정리
개념을 정리하기에 앞서 간단한 예제 상황부터 짚고 넘어가겠습니다.
주어진 텍스트가 스팸 메일일 확률을 계산하는 ML 모델을 짠다고 해봅시다. 이 때, 텍스트의 확률변수를 $X$, 클래스의 확률변수를 $Y$라고 해보겠습니다. $y_1$이 정상 메일, $y_2$가 스팸 메일에 해당합니다. 예를 들어, 입력 텍스트에 "특가"라는 텍스트가 포함되었을 경우 스팸일 확률 $P\left(y_2\mid X=x\right)=0.95$와 같이 나왔습니다.
이 소프트웨어로 지금까지 받은 메일을 확인했더니, 70%(0.7)은 스팸 메일이고, 나머지 30%(0.3)은 정상 메일이었습니다. 스팸 메일의 90%에는 "대출"이라는 단어가 포함되어 있고, 정상 메일의 3%는 "대출"이라는 단어를 포함했습니다. 이때, "대출"이라는 단어가 들어있는 메일이 스팸 메일일 확률을 구하는 것이 이번 예제의 목적입니다.
지난 포스트의 조건부확률의 정의를 다시 짚고 넘어가볼까요? 특정한 사건 $X$가 발생했을 때, 사건 $Y$가 발생할 조건부확률은 아래와 같았습니다.
$$P\left(Y\mid X\right) = \frac{n\left(X\cap Y\right)}{n\left(X\right)}$$
이 정의대로라면 주어진 문제 상황에서 구하고자 하는 확률은 $P\left(Y=y_1\mid X=x\right)$가 됩니다. 그러나 여기서 문제는 우리가 아직 메일에 "대출"이라는 단어가 들어있을 확률 $P\left(x\right)$를 모른다는 점입니다. 이러한 상황에서 조건부확률을 구하기 위해 베이즈 정리를 도입하게 됩니다.
def) 베이즈 정리 (Bayes' Theorem)
$$P\left(Y\mid X\right) = \frac{P\left(X\mid Y\right)P\left(Y\right)}{P\left(X\right)}$$
$$\left(posterior\propto likelihood\times prior\right)$$
$P\left(Y\mid X\right)$: 특정 텍스트가 주어졌을 때 그것이 특정 클래스일 확률 (a.k.a. 사후 확률, posterior)
$P\left(X\mid Y\right)$: 특정 클래스가 주어졌을 때 그것에서 특정 텍스트가 나올 확률
$P\left(Y\mid X\right)$: 특정 텍스트가 나올 확률
$P\left(Y\mid X\right)$: 특정 클래스가 나올 확률
위와 같이 $P\left(Y\mid X\right)$를 직접 계산하는 것이 어려울 때 베이즈 정리를 사용합니다. 이 정리만으로도 해결할 수 있는 확률 문제가 상당히 풀리는 경우가 많습니다(전부 다는 아니더라도).
유도
derivation) 조건부확률의 정의
$$P\left(A\mid B\right) = \frac{P\left(A\cap B\right)}{P\left(B\right)}$$
에서 $P\left(A\cap B\right)$에 대하여 정리하면,
$$P\left(A\cap B\right) = \frac{P\left(A\mid B\right)}{P\left(B\right)}$$
같은 방법으로,
$$P\left(B\cap A\right) = \frac{P\left(B\mid A\right)}{P\left(A\right)}$$
입니다. 따라서,
$$P\left(A\cap B\right) = P\left(A\mid B\right)P\left(B\right)=P\left(B\mid A\right)P\left(A\right)$$
이므로,
$$\therefore P\left(A\mid B\right) = \frac{P\left(B\mid A\right)P\left(A\right)}{P\left(P\right)}$$
다시 문제로 돌아와서...
따라서 $P\left(대출\right)$를 먼저 구하면,
$$\begin{matrix}
P\left(대출\right) &=& P\left(대출\cap 스팸\right) + P\left(대출\cap 정상\right) \
&=& P\left(대출\mid 스팸\right)P\left(스팸\right) + P\left(대출\mid 정상\right)P\left(정상\right) \
&=& 0.9\times 0.7 + 0.03\times 0.3 &=& 0.639
\end{matrix}$$
확률모델
def) 확률모델(Probabilistic Models): 확률을 출력하는 모델
일반적인 분류 모델 $P\left(y\mid x\right)$은 아래와 같이 베이즈 정리를 이용하여 예측 결과 $\hat{y}$를 구합니다.
$$\hat{y}=argmax_y P\left(y\mid x\right)=argmax_y \frac{P\left(x\mid y\right)P\left(y\right)}{P\left(x\right)}=argmax_y P\left(x\mid y\right)P\left(y\right)$$
여기서 $argmax$는 주어진 확률값을 최대로 만드는 $y$의 값을 의미합니다. 가능한 모든 클래스 중 가장 확률이 높은 클래스가 정답에 해당하므로 이를 사용합니다. 이러한 내용은 자연어 처리 또는 이미지 분류 등 여러 모델에서 사용될 수 있기 때문에 이러한 조건부확률과 베이즈 정리를 알아두는 것이 좋다고 합니다. 특히 이러한 법칙을 황금 법칙(Golden Rule)이라고 언급할 정도로 중요한 개념으로써 강조합니다.
최대 우도 추정
def) 최대 우도 추정(Maximum Likelihood Estimation): 가능도(likelihood)가 가장 높은 클래스를 선택하는 방법
우도 또는 가능도(likelihood)가 최대인 클래스를 선택하는 기법입니다. $X$를 데이터 또는 특징(feature)라고 말하며, 여기서는 광고성 단어의 개수(예컨대, "특가" 등)라고 해보겠습니다. 현재 예시에서는 아래 그림과 같이 $X \ge 5$라면 스팸으로 분류된다고 추정을 할 수 있습니다.(곡선은 임의의 개형을 가정하고 그린 겁니다! 특별한 의미가 있는 것이 아닙니다)
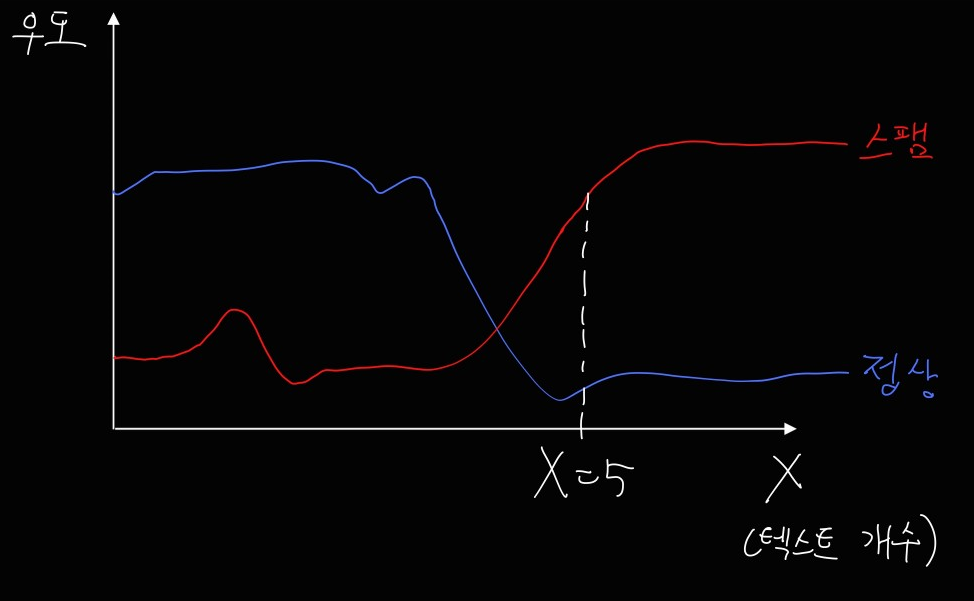
최대 우도 추정 시 유의할 점
앞서 우리는 사후확률을 직접적으로 계산하기 어려울 때 가능도(우도)를 이용한다고 했습니다. 문제는 가능도만으로 사후확률을 완전히 근사할 수 없다는 데 있습니다.
만약 prior에 해당하는 $P\left(Y\right)$가 균등분포를 따르지 않고, 따라서 전체 메일 중에서 스팸 메일의 수가 정상 메일의 수보다 적다고 하면, 분포는 판이하게 바뀔 수도 있습니다. 애초에 스팸의 개수 자체가 적어서 스팸이 정상 메일의 절반 밖에 안 된다고 하면 아래와 같이 바뀝니다.

따라서 이러한 분포를 추가로 반영해주면, 더욱 정교한 분류를 할 수 있습니다. 이 경우에는 $X \ge 6$이라면 스팸메일로 분류할 수 있겠습니다. 정리하자면, prior를 고려할 때 posterior를 더욱 잘 계산할 수 있습니다.
9일차 후기
베이즈 정리는 ML 분야에서 지속적으로 등장하는 개념으로, 최신 인공지능 기술보다는 다소 뒤떨어지지만 워낙 기본적인 모델로 자주 언급되기 때문에 잘 정리하면 좋습니다. 아예 Naive Bayes' Classifier라는 개념이 있을 정도이니 본격적으로 ML 모델 학습을 시작하면 자주 들어와서 복습해줍시다. 안 그러면 저처럼 또 공부해야 됩니다...
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
* 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'[패스트캠퍼스 환급챌린지]딥러닝 > Chapter 1. 통계' 카테고리의 다른 글
| [패스트캠퍼스][환급 챌린지]Chapter 1. 딥러닝을 위한 통계 01-11 분산과 표준편차 (0) | 2023.03.02 |
|---|---|
| [패스트캠퍼스][환급 챌린지]Chapter 1. 딥러닝을 위한 통계 01-10 평균과 기대값 (0) | 2023.03.01 |
| [패스트캠퍼스][환급 챌린지]Chapter 1. 딥러닝을 위한 통계 01-08 조건부확률 (0) | 2023.02.27 |
| [패스트캠퍼스][환급 챌린지]Chapter 1. 딥러닝을 위한 통계 01-07 결합확률과 주변확률 (1) | 2023.02.26 |
| [패스트캠퍼스][환급 챌린지]Chapter 1. 딥러닝을 위한 통계 01-06 독립변수와 종속변수 (0) | 2023.02.25 |