02-08 이진 탐색 트리
이진 탐색 트리는 다수의 데이터를 관리하는 데 적합한 트리(tree) 자료구조의 기본이 되는 구조이기 때문에 반드시 짚고 넘어가야 합니다.
트리
def) 트리 (tree): 계층적인 구조를 표현할 때 사용할 수 있는 자료구조
루트 노드 (root node): 부모가 없는 최상위 노드
리프 노드 (leaf node): 자식이 없는 노드
깊이 (depth): 루트 노드에서의 길이(length, 출발 노드에서 목적지 노드까지 거쳐야 하는 간선의 수)
높이 (height): 루트 노드에서 가장 깊은 리프 노드까지의 길이
그럼 먼저 트리 구조가 뭔지 간단하게 알아보겠습니다. 다음과 같이 나무를 뒤집어놓은 듯한 자료구조인 트리는 최상위 노드인 루트와 더 이상 자식이 없는 리프(단말) 노드까지 이어지는 일련의 연결입니다. 트리의 각 노드는 부모-자식 관계가 성립한다고 보며, 같은 루트 노드를 부모로 둔 여러 자식 노드들은 형제 관계라고 합니다. 루트가 같은 형제 노드들은 루트로부터의 길이 내지는 깊이가 동일합니다.

이진 트리
def) 이진 트리 (Binary Tree): 최대 2개의 자식을 가질 수 있는 트리
이진 트리는 최대 2개까지 자식을 가지는 트리를 뜻합니다. 구조는 대략 아래 그림과 같습니다.

이진 탐색 트리
def) 이진 탐색 트리 (Binary Search Tree): 최대 2개의 자식을 가질 수 있는 트리
이어서 오늘 알아볼 이진 탐색 트리입니다. 이진 탐색 트리는 다수의 데이터를 관리(즉, 조회, 저장, 삭제)하기 위한 가장 기본적인 자료구조 중 하나입니다. 이진 탐색 트리의 성질은 왼쪽 자식 노드보다는 부모 노드가 커야 하고, 부모 노드보다는 오른쪽 자식 노드가 커야 합니다. 아래 그림을 보면 이게 무슨 말인지 알 수 있습니다. 이진 탐색이라는 알고리즘에 특화되어 있는 트리 자료구조이기 때문에 매우 중요하게 다루어집니다.

위 그림을 조금 더 풀어서 설명해보자면, 각 노드에 적혀있는 숫자들을 키(key)라고 합니다. 왼쪽 자식 노드보다 부모 노드가 커야 한다는 뜻은 특정 노드의 키 값보다 왼쪽 자식 노드의 키 값이 더 작다는 뜻이며, 반대로 부모 노드보다 오른쪽 자식 노드가 커야 함은 특정 노드의 키 값보다 오른쪽 자식 노드의 키 값이 더 크다는 뜻입니다.
또한, 그림 왼쪽을 보시면 2-3-4-5-6의 키를 갖는 노드들 또한 이진 트리의 특성을 그대로 가지고 있는 것을 알 수 있습니다. 이와 같이 특정한 노드의 왼쪽 서브 트리(하위 트리), 오른쪽 서브 트리 역시 모두 이진 탐색 트리가 된다는 특성이 있습니다.
이진 탐색 트리 - 삽입 연산
그럼 이진 탐색 트리의 연산에 대해 알아보죠. 먼저 삽입 연산입니다. 삽입 연산은 루트 노드에서 출발하여 아래로 내려오면서, 삽입할 위치를 스스로 찾는 특징이 있습니다. 이 때, 삽입할 노드의 키 값이 작으면 왼족으로, 키 값이 크면 오른쪽으로 삽입합니다.
아래 예시에서는 [7, 4, 5, 9, 6, 3, 2, 8]의 노드로 구성된 이진 탐색 트리를 사용합니다. 그림에서 노드가 삽입되는 순서를 빨간 글씨로 적었습니다.

이진 탐색 트리 - 조회 연산
조회 연산은 삽입 연산과 거의 동일합니다. 루트에서 출발해 아래로 내려오면서, 찾고자 하는 원소를 조회하기만 하면 됩니다. 예를 들어 5번 노드를 조회하고 싶다면, 루트인 7번 노드에서 시작해, 7보다 작으니 왼쪽으로, 4보다는 크기 오른쪽으로 이동함으로써 5번 노드에 다다르게 됩니다.
이진 탐색 트리 - 삭제 연산
삭제는 삽입과 조회에 비해 상대적으로 복잡합니다. 삭제 연산의 경우는 크게 세 가지 케이스로 나뉘곤 합니다.
- 왼쪽 자식이 없는 경우 → 오른쪽 자식으로 대체
- 오른쪽 자식이 없는 경우 → 왼쪽 자식으로 대체
- 양쪽 자식이 모두 있는 경우 → 오른쪽 서브 트리에서 가장 작은 노드로 대체
아래 예시를 보면서 설명해보죠. 여기서 지우고자 하는 건 루트에 해당하는 7번 노드입니다. 양쪽 자식이 모두 있기 때문에 오른쪽 서브 트리 9-8에서 가장 작은 노드로 대체해야 합니다. 따라서 대체할 노드는 8번 노드가 되겠습니다.

트리의 순회
위의 세 연산으로 트리를 구성하는 뼈대가 되는 로직에 대해 알아봤습니다. 그렇다면 트리에 포함된 모든 정보를 출력하려면 어떤 방법을 쓸 수 있을까요? 이때 사용되는 기법이 순회(traversal)입니다.
def) 순회 (Traversal): 트리의 모든 노드를 특정한 순서 또는 조건에 따라서 방문하는 방법
트리의 순회는 그 방식에 따라 크게 세 가지로 나뉩니다.
- 전위 순회 (Pre-order traverse): 루트 방문 → 왼쪽 자식 방문 → 오른쪽 자식 방문
- 중위 순회 (In-order traverse): 왼쪽 자식 방문 → 루트 방문 → 오른쪽 자식 방문
- 후위 순회 (Post-order traverse): 왼쪽 자식 방문 → 오른쪽 자식 방문 → 루트 방문

위 이미지의 이진 트리를 예로 들면, 1,2,3,의 정의에 따라 각각의 순회를 따르면 아래와 같습니다.
- 전위 순회: A - B - D - E - C - F - G
- 중위 순회: D - B - E - A - F - C - G
- 후위 순회: D - E - B - F - G - C - A
트리의 순회 - 레벨 순회
def) 레벨 순회 (Level Order Traversal): 낮은 레벨(루트 노드)부터 높은 레벨까지 순차적으로 방문하는 기법
순회 중에는 단순히 높이 순으로 출력하는 레벨 순회도 존재합니다. 루트 노드에서부터 너비 우선 탐색(BST)이라는 연산을 진행해 가까운 노드를 방문하게 됩니다. 위의 이미지를 예시로 쓰면 A - B - C - D - E - F - G의 순서로 출력됩니다.
이진 탐색 트리의 구현
트리를 파이썬에서 구현하기 전에 먼저 짚고 넘어가자면, 어떤 메서드가 다른 메서드 내에서 사용될 경우 그 이름 앞에 언더바(_)를 붙입니다. 아래 코드 예시는 맨 아래의 파이썬에서의 구현 파트의 일부를 가져온 것입니다.
def search(self, key):
return self._search(self.root, key)
def _search(self, node, key):
if node is None or node.key == key:
return node
if node.key > key:
return self._search(node.left, key)
elif node.key < key:
return self._search(node.right, key)이진 탐색 트리의 단점 - 편향 이진 트리
이진 탐색 트리의 단점으로는 편향 이진 트리(skewed binary tree)가 생성될 수 있다는 점입니다. 편향 이진 트리는 다음 2개의 특성을 가집니다.
- 같은 높이의 이진 트리 중 최소 개수의 노드 개수를 가진다.
- 왼쪽 혹은 오른쪽 한 방향에 대해서만 서브 트리를 가진다.

위 그림은 편향 이진 트리의 한 가지 예시를 나타낸 겁니다. 매 깊이마다 노드는 1개씩 밖에 없으며, 오직 왼쪽으로만 치우쳐서 노드가 생성된다는 점이 특징입니다.
이진 탐색 트리의 시간복잡도
이진 탐색 트리의 높이를 $H$라 하면, 엄밀한 의미의 시간복잡도는 $O\left(H\right)$가 됩니다. 이상적인 경우에는 $H=\log_2 N$으로 볼 수 있습니다. 하지만, 최악의 경우, 그러니까 앞서 설명한 편향 이진 트리의 경우는 $H=N$인 케이스에 해당합니다. 이렇게 최악의 경우를 가정했을 때 각 연산에 대한 시간복잡도는 아래와 같이 정리됩니다.
| 조회 | 삽입 | 삭제 | 수정 | |
|---|---|---|---|---|
| 균형 잡힌 이진 탐색 트리 | $O\left(\log N\right)$ | $O\left(\log N\right)$ | $O\left(\log N\right)$ | $O\left(\log N\right)$ |
| 편향 이진 탐색 트리 | $O\left(N\right)$ | $O\left(N\right)$ | $O\left(N\right)$ | $O\left(N\right)$ |
[참고] 균형 잡힌 트리: AVL 트리
이 부분은 꼭 알아야 하는 부분은 아니지만, 개인적으로 공부하고 싶은 분들을 위해 이런 것도 있다 하고 소개된 부분입니다.
지금까지 정리한 것처럼 이진 탐색 트리를 균형잡힌 형태로 구현하는 것이 가장 이상적입니다. 하지만 이진 탐색 트리의 기본적인 구조는 이러한 균형을 보장할 수 없기 때문에, 원한다면 나중에 AVL 트리라는 키워드로 공부하시는 걸 추천드립니다.
쉽게 정리하자면 AVL 트리는 균형이 갖추어진 이진 탐색 트리로, 간단한 구현 과정으로 완전 이진 트리에 가까운 형태를 유지하도록 합니다.
파이썬에서의 구현
파이썬으로 구현해본 이진 탐색 트리입니다. 연산이 많다보니 클래스가 복잡하게 되어 있는 것 같지만, 위에서 설명한 내용을 코드로 옮겨본 것입니다.
그게 어려워서 그렇지
from collections import deque
class Node:
def __init__(self, key):
self.key = key
self.left = None
self.right = None
class BinarySearchTree:
def __init__(self):
self.root = None
def search(self, key):
return self._search(self.root, key)
def _search(self, node, key):
if node is None or node.key == key:
return node
if node.key > key:
return self._search(node.left, key)
elif node.key < key:
return self._search(node.right, key)
def insert(self, key):
self.root = self._insert(self.root, key)
def _insert(self, node, key):
if node is None:
return Node(key)
if node.key > key:
node.left = self._insert(node.left, key)
elif node.key < key:
node.right = self._insert(node.right, key)
return node
def delete(self, key):
self.root = self._delete(self.root, key)
def _delete(self, node, key):
if node is None:
return None
if node.key > key:
node.left = self._delete(node.left, key)
elif node.key < key:
node.right = self._delete(node.right, key)
else:
if node.left is None:
return node.right
elif node.right is None:
return node.left
node.key = self._get_min(node.right)
node.right = self._delete(node.right, node.key)
return node
def _get_min(self, node):
key = node.key
while node.left:
key = node.left.key
node = node.left
return key
def preorder(self):
self._preorder(self.root)
def _preorder(self, node):
if node:
print(node.key, end=" ")
self._preorder(node.left)
self._preorder(node.right)
def inorder(self):
self._inorder(self.root)
def _inorder(self, node):
if node:
self._inorder(node.left)
print(node.key, end=" ")
self._inorder(node.right)
def postorder(self):
self._postorder(self.root)
def _postorder(self, node):
if node:
self._postorder(node.left)
self._postorder(node.right)
print(node.key, end=" ")
def levelorder(self):
return self._levelorder(self.root)
def _levelorder(self, node):
if node is None:
return
result = []
queue = deque()
queue.append((0, node)) # (level, node)
while queue:
level, node = queue.popleft()
if node:
result.append((level, node.key))
queue.append((level+1, node.left))
queue.append((level+1, node.right))
for level, key in result:
print(f"level: {level}, key: {key}")
def to_list(self):
return self._to_list(self.root)
def _to_list(self, node):
if node is None:
return []
return self._to_list(node.left) + [node.key] + self._to_list(node.right)
arr = [7, 4, 5, 9, 6, 3, 2, 8]
bst = BinarySearchTree()
for x in arr:
bst.insert(x)
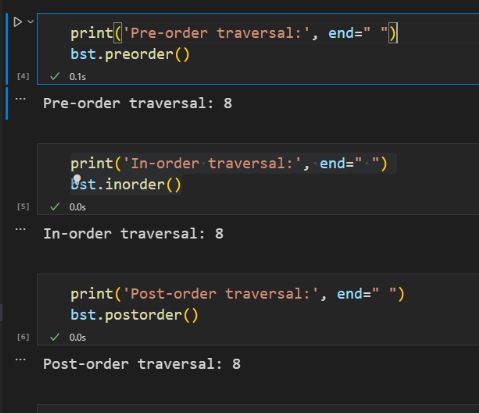
print('Pre-order traversal:', end=" ")
bst.preorder()
print('\nIn-order traversal:', end=" ")
bst.inorder()
print('\nPost-order traversal:', end=" ")
bst.postorder()
print('\n[Level-order traversal]')
bst.levelorder()
bst.delete(7)
print('Pre-order traversal:', end=" ")
bst.preorder()
print('\nIn-order traversal:', end=" ")
bst.inorder()
print('\nPost-order traversal:', end=" ")
bst.postorder()
print('\n[Level-order traversal]')
bst.levelorder()
bst.delete(4)
print('Pre-order traversal:', end=" ")
bst.preorder()
print('\nIn-order traversal:', end=" ")
bst.inorder()
print('\nPost-order traversal:', end=" ")
bst.postorder()
print('\n[Level-order traversal]')
bst.levelorder()
bst.delete(3)
print('Pre-order traversal:', end=" ")
bst.preorder()
print('\nIn-order traversal:', end=" ")
bst.inorder()
print('\nPost-order traversal:', end=" ")
bst.postorder()
print('\n[Level-order traversal]')
bst.levelorder()
print(bst.to_list())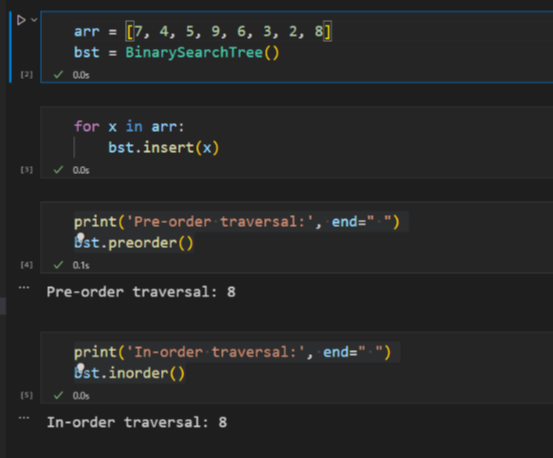





25일차 후기
파면 팔수록 느끼는 건 왜 이런 걸 컴공과 외의 학과에서 머신러닝을 가르칠 때는 안 가르쳐줬을까 하는 의문... 언급이라도 해줬으면 어떻게든 더 고민하고 공부하면서 실력이 늘 수 있지 않았을까 하는 생각이 듭니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
* 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'[패스트캠퍼스 환급챌린지]딥러닝 > Chapter 2. 자료구조' 카테고리의 다른 글
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료구조 02-10 그래프의 표현 (0) | 2023.03.18 |
|---|---|
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료구조 02-09 우선순위 큐 (0) | 2023.03.17 |
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료구조 02-07 덱 (1) | 2023.03.15 |
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료구조 02-06 큐 (0) | 2023.03.14 |
| [패스트캠퍼스][환급 챌린지]Chapter 2. 딥러닝을 위한 자료구조 02-05 스택 (0) | 2023.03.13 |