03-07 사전 자료형과 집합 자료형
딥러닝 공부를 시작하고 코딩에도 어느 정도 숙달될 무렵까지도 저는 이 두 자료형의 중요성을 깨닫지 못했습니다. 그리고 함수에 키워드를 추가할 일이 생기자 그제서야 이걸 배운 이유를 깨우쳤습니다...
항상 깨달음이 늦어
오늘 소개할 이 두 자료형은 특정한 원소의 존재 여부를 빠르게 확인하고 추가/삭제할 수 있습니다.
들어가기에 앞서
사전 자료형의 명칭은 영문 명칭인 딕셔너리(dictionary)를 직역한 이름입니다. 파이썬을 다룬 서적마다 다르기는 하지만 보통 딕셔너리라는 영문명 그대로 사용하기 때문에 이 포스트에서도 딕셔너리 자료형이라는 이름이 혼용되었음을 알려드립니다.
또한 다른 프로그래밍 언어 등에서는 연관 배열(associative array), 해쉬(hash) 등으로 부르기도 합니다.
사전(딕셔너리) 자료형
우리가 사전을 찾으면 특정한 단어가 먼저 나오고, 그 단어의 뜻이 뒤따라옵니다. 이와 비슷하게 사전(dictionary) 자료형 또는 딕셔너리 자료형은 키(key)와 밸류(value)로 구성되는 한 쌍의 데이터들로 구성됩니다. 실제 사전에 비유하자면 우리가 찾고자 하는 단어가 키에 해당하고, 그 뜻은 밸류에 해당합니다. 키와 데이터를 묶어서 표현하면 대략 다음과 같이 부를 수 있을 겁니다.Dictionary_data[key] = value
리스트가 대괄호 []로, 튜플이 소괄호 ()로 구분된 것과 같이 딕셔너리 자료형은 중괄호 {}로 구분됩니다. 이 때, 키와 밸류를 함께 입력해 초기화하지 않을 경우 (예를 들어 {5, 6, 7, 8, 9}) 아래에서 설명한 집합 자료형으로 지정됩니다.
arr1 = ['컴퓨터', '키보드', '모니터']
arr2 = ['computer', 'keyboard', 'monitor']
data = {}
for i in range(len(arr1)):
data[arr1[i]] = arr2[i]
print(data)
딕셔너리 자료형의 모든 원소는 키와 밸류의 한 쌍으로 구성되기 때문에, 이들의 키만 또는 밸류만 확인하는 메서드가 있습니다. 키를 확인할 때는 keys() 메서드를 사용합니다.
data = {}
data['apple'] = '사과'
data['banana'] = '바나나'
data['carrot'] = '당근'
for key in data.keys():
print("key:", key, ", value:", data[key])
딕셔너리 자료형은 특정 데이터의 등장 횟수를 셀 때 효과적으로 사용할 수 있습니다. 프로그래밍을 할 때 동일한 데이터가 얼마나 자주 등장하는지를 세어야 하는 경우가 많음을 생각하면 이 또한 유용한 방법 중 하나입니다.
하지만 암만 봐도 count() 쓰는 게 더 편해보입니다
data = [1, 3, 3, 5, 4, 3, 1, 4]
counter = {}
for x in data:
if x not in counter:
counter[x] = 1
else:
counter[x] += 1
print(counter)
집합 자료형
집합(set) 자료형은 수학에서 등장하는 집합과 관련이 있습니다. 데이터의 중복을 허용하지 않고, 순서가 상관없을 때 사용하는 자료형이라는 점에서 수학의 집합 특성을 가지고 있음을 알 수 있죠. 때문에 리스트 등의 다른 자료형에서 중복되는 특정 데이터를 지우고 싶을 때, 혹은 특정 데이터가 등장한 적 있는지 체크할 때 효과적입니다.
특정한 괄호를 쓰면 해당 자료형을 갖는 빈 목록을 지정할 수 있는 리스트, 튜플, 딕셔너리와 달리 집합 자료형은 set() 메서드를 이용해 생성합니다. 달리 말하면, set(리스트 이름) 같은 방식으로 다른 자료형을 집합 자료형으로 변환하는 것도 가능하다는 겁니다. 사실 리스트와 튜플에도 똑같은 메서드가 있지만 이건 밑에서 짧게 다루기로 하고....
리스트에서 append와 insert 메서드로 원소를 집어넣은 것과 같이, 집합 자료형은 add() 메서드를 가지고 있습니다. 다만, 앞서 설명한 것과 같이 집합 자료형은 원소의 순서를 따지지 않기 때문에 어느 인덱스에 원소를 추가할지에 대한 관련이 있는 리스트 자료형과 달리 메서드를 하나만 가지고 있습니다.
data = [1, 3, 3, 5, 4, 3, 1, 4]
visited = set()
for x in data:
if x not in visited:
visited.add(x)
else:
print("Duplicate element detected:", x)
print("Unique numbers:", visited)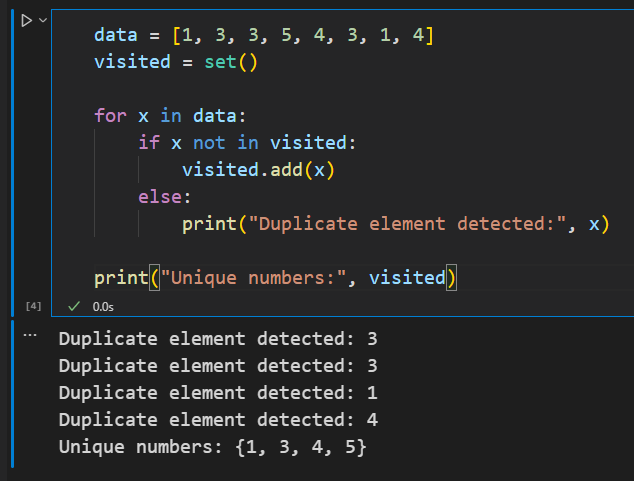
반대로 원소를 제거할 때는 remove() 메서드를 사용합니다.
data = {5, 6, 7, 8, 9}
print(data)
data.remove(7)
print(data)
arr = list(data)
print(type(data))
print(type(arr))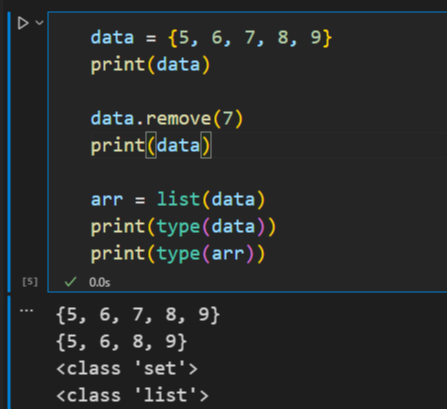
수학에서 집합을 설명할 때 합집합, 교집합, 차집합 등의 개념을 함꼐 소개하곤 합니다. 이와 관련된 연산자는 아래와 같습니다.
- 합집합:
| - 교집합:
& - 차집합:
-
data1 = {3, 4, 5, 6, 7}
data2 = {6, 7, 8, 9, 10}
data = data1 | data2
print(data)
data = data1 & data2
print(data)
data = data1 - data2
print(data)
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
* 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'[패스트캠퍼스 환급챌린지]딥러닝 > Chapter 3. 파이썬' 카테고리의 다른 글
| [패스트캠퍼스]Chapter 3. 딥러닝을 위한 파이썬 03-09 조건문 (0) | 2023.04.12 |
|---|---|
| [패스트캠퍼스]Chapter 3. 딥러닝을 위한 파이썬 03-08 참과 거짓 자료형 (0) | 2023.04.10 |
| [패스트캠퍼스]Chapter 3. 딥러닝을 위한 파이썬 03-06 리스트 자료형과 튜플 자료형 (0) | 2023.03.29 |
| [패스트캠퍼스]Chapter 3. 딥러닝을 위한 파이썬 03-05 문자열 자료형 (0) | 2023.03.27 |
| [패스트캠퍼스][환급 챌린지]Chapter 3. 딥러닝을 위한 파이썬 03-04 수 자료형 (0) | 2023.03.24 |