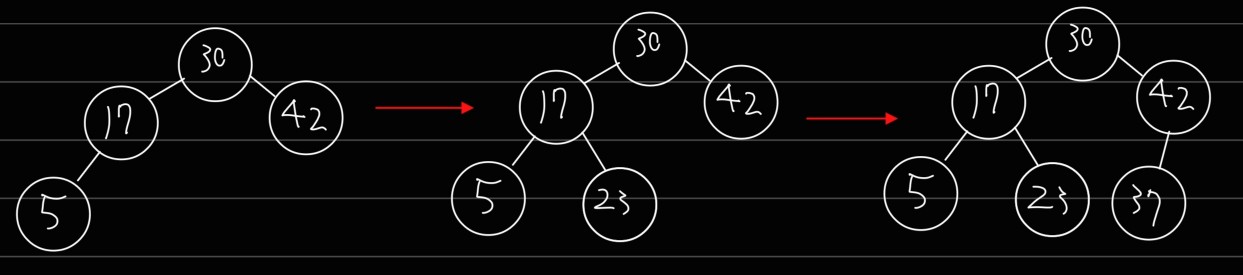
02-09 우선순위 큐 우선순위 큐는 다양한 알고리즘 및 프로그램에서 사용 빈도가 높은 중요한 구조입니다. 이번 포스트에서는 우선순위 큐에 대한 일반적인 얘기를 먼저 한 뒤, 우선순위 큐의 가장 대표적인 예시인 힙(heap)을 알아보겠습니다. 우선순위 큐 def) 우선순위 큐 (Priority Queue): 우선순위에 따라서 데이터를 추출하는 자료구조 우선순위 큐는 큐(queue) 자료구조의 변형 형태로 볼 수 있으며, 컴퓨터 운영체제(OS)나 온라인 게임 매칭 등에 사용되는 구조입니다. 운영체제의 경우, 우리가 음악을 들으면서 문서 작업을 하는 등 한 컴퓨터에서 여러 작업을 동시에 작동시키는 경우가 많습니다. 당장 저만 해도 블로그 정리할 때 항상 유튜브 브금을 깔아놓습니다 이 때 프로그램의 우선순위를..